
Basic elements of the Flash Virtualization Platform (FVP), part 2. Using your own platform or file system
One of the topics I discussed with Satyam and Murali Vilayannur was the file system that is used to store data on flash devices. The following noteworthy facts should be kept in mind: Satyam created VMFS3, Murali was the leading developer of VMFS5. From this point of view, the use of VMFS would seem obvious. However, the big surprise for me was the fact that for flash devices we don’t use VMFS, an even bigger surprise was that we don’t use the file system at all.
Why not VMFS?
File systems provide features that are not required and sometimes even conflict with the requirements of the platform that processes active I / O on flash devices. One of the biggest problems with using a file system similar to VMFS on a flash device is that it is optimized for SAN storage systems and their data management models; Satyam wrote an article about this for ACM while working in VMware. Unfortunately, this makes the file system an inappropriate tool for FVP tasks.
Direct address file systems overload flash devices, reducing their lifespan, do not optimally process arbitrary I / O operations, test their (often very fragile) garbage collection algorithms for strength, and their objects (files and directories) are less suitable for virtual machine level and quality of service management, which is extremely important for FVP tasks. The next section will detail the problem of managing data on flash devices, but for now a brief conclusion: if your flash device is expensive for you, do not put a direct addressing file system on it.
File systems also provide capabilities that greatly exceed the needs of FVP. For example, disk locks. VMFS has an advanced distributed locking manager that controls the access of different ESXi hosts to disks. FVP manages the local disks of the host and does not require locks on other hosts, as a result, the distributed lock manager becomes completely superfluous. The same can be said about POSIX compatibility and distributed transactions. And so on.
Low-level flash operations
Here's an example of how writing to flash devices is fundamentally different from recordings on hard drives. Flash can not overwrite existing data. Data in flash memory can be written only on a blank page. A feature of flash memory is that recording can be done by pages, and erasing can be done only in blocks. What is a page and what is a block? Flash stores data in cells; cells are combined into pages (4 KB); pages are grouped into blocks. Most manufacturers combine 128 pages into one block. If you want to erase the page, then you need to erase the entire block. All necessary data from other pages should be saved somewhere else. It is widely known that flash devices have a limited number of write and erase cycles.
Consequently, a random I / O write can have a greater impact than you thought. The problem is that most file systems were developed in the 80s and 90s and have not progressed since that time. File systems do not take into account the performance degradation they cause to flash devices using low-level operations designed for hard drives; Most flash device manufacturers implement various mechanisms to account for progressive performance degradation. With the help of several schemes, we consider these mechanisms and find out why fragmentation has such an effect on flash devices.
Wear management
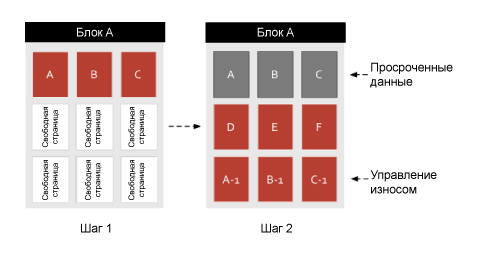
Note, for simplicity, I decided to show 9 pages in one block instead of 128 pages per block.
Let's start with the wear management process. In this example, the application has already created the data and recorded it in pages A, B and C in block 1 (Step 1). New data arrives (Step 2), which is written to pages D, E, and F. The application updates the previous data (AC) and instead of using the previous pages, the flash device continues to use the new pages. This new data is labeled A-1, B-1 and C-1. Distributing records as evenly as possible is called “wear management.” Old pages are now marked as expired.
Garbage collection and multiple entry
In this example, block A is full, what happens if the space available to the user for recording has run out and new data arrives?
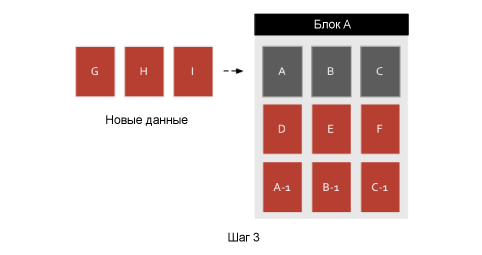
Flash will copy current data to empty cells. Actual data in the block is read and written to another block. Overdue data will remain in its pages and will be erased along with the rest of the block pages. This process is called "garbage collection."
Garbage collection is fine, but the multiple entry that occurs during its operation causes significant damage to flash devices. In order to record 3 pages, the flash device must read 6 pages and write the 6 pages to another place before it can write new data. And do not forget about the erase cycle. Suppose a scenario in which the disk is full, where will we (temporarily) move the data before recording new data? In my diagram, I added block B for this option. In order to do this in a real situation (when using the file system), you need to allocate excess space reserved by the controller flash.
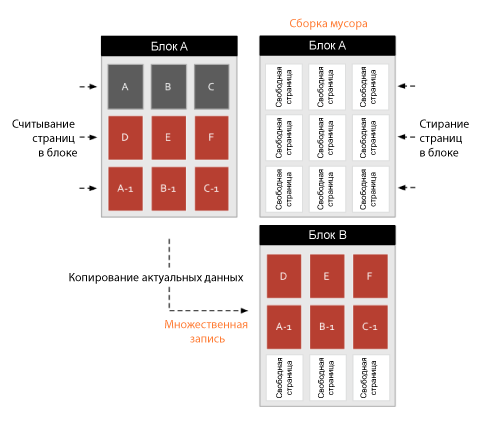
Excess space
Flash capacity can be reserved for processes managed by a flash controller. This can be done both by the manufacturer of the flash device and by the user. For example, when you buy a 160 GB flash PCIe accelerator, in fact, you get a 192 GB card. 160 GB are available to the user and 32 GB is reserved additionally for flash-level controller-level operations, such as garbage collection, error correction, and controller firmware. When you purchase a non-industrial SSD drive, you usually get a little reserved excess space. When formatting this flash device in any file system, you should be aware of these features and, possibly, reserve additional space outside the available capacity. There are currently no standardized scaling recommendations, so you have to make choices based on your own experience. In the worst case, you will find yourself with a fragmented disk and the SSD will have to constantly transfer data to write new ones. Imagine the children playing tag, only the pattern of movement is a little more complicated.
Reconsidering data management on flash devices
PernixData engineers have developed a new format for managing data on flash devices for FVP. Details will be disclosed in the following articles, and now a few fundamental points.
Optimized for flash
The format is designed to store temporary I / O data with the minimum possible set of metadata, and work with a flash device with the maximum available performance for it. It converts random entries to consecutive ones, to take advantage of higher flash performance in sequential write mode. This reduces the number of redundant data overwrites and erase cycles. And the algorithm does not contain the inherited limitations of file systems, such as large block sizes, directories, files, long transactions, lock managers, etc.
Dynamically shared capacity between virtual machines
Thanks deep integration With VMkernel, FVP can track data blocks and determine whether their virtual machine is reading or writing. Independently tracking such operations, the platform can scale read and write buffers in space allocated for the virtual machine. FVP can cache or delete an arbitrary set of virtual machine data from the cache. In contrast, the data evacuation policy on the traditional file system for a flash device will be suboptimal and will result in multiple rewrites, since the file system can only write data to the end of the file or delete blocks from the end as well.
It also means that you do not need to assign a static cache space configuration for each virtual machine, as it would be if you use a file system with direct addressing. It was a great decision for us; user experience from the product should be as intuitive as possible.
I quote our product manager Bala: "The elegance of the product, in my opinion, is that it performs basic tasks, NOT requiring any new or unusual actions from the user."
In terms of everyday work, this is excellent: you do not need to pre-scale the cache for each virtual machine. This means that you do not need to know and predict the future use of flash - FVP will do everything for you. The lack of a hard resource allocation means the lack of underutilization of flash by unloaded virtual machines and the appearance of redundant block cleaning cycles for active virtual machines with insufficient flash cache size. This minimizes the problem of multiple recordings and ensures maximum performance and reliability of flash devices.
Original article .
Since 2016, FVP withdrawn from sale.
Why not VMFS?What is a page and what is a block?
Suppose a scenario in which the disk is full, where will we (temporarily) move the data before recording new data?