
Абсолютная и взвешенная частота слов в тексте
- Абсолютная и взвешенная частота слов: введение
- Простая частота слов с использованием defaultdict
- Взвешенная частота слов
- Следующие шаги и улучшения
Важный набор метрик в интеллектуальном анализе текста относится к частоте слов (или любого токена) в определенном корпусе текстовых документов. Однако вы также можете использовать дополнительный набор метрик в тех случаях, когда каждому документу присваивается числовое значение, описывающее определенный атрибут документа.
Некоторые примеры:
- Твиты и их количество заданий.
- URL-адреса и их просмотры страниц и отказов.
- Названия фильмов и их валовой доход.
- Ключевые слова и их показы, клики и конверсии.
В этом уроке
- Сначала вы пройдете процесс создания простой функции, которая вычисляет и сравнивает абсолютное и взвешенное вхождение слов в совокупность документов. Иногда это может выявить скрытые тенденции и агрегаты, которые не обязательно ясны, если взглянуть на десятку или около того значений. Они также часто могут отличаться от абсолютной частоты слов.
- Затем вы увидите реальный набор данных (названия фильмов и валовой доход) и надеетесь обнаружить скрытые тенденции. Тизер: любовь придет как-нибудь!
- Вы будете использовать Python в качестве языка программирования и использовать структуру данных defaultdict модуля коллекций для тяжелой работы, а также pandas DataFrames для управления окончательным выводом.
Абсолютная и взвешенная частота слов: введение
Предположим, у вас есть два твита, и их содержание и количество показов (просмотров) выглядят следующим образом:
Tweet Text Views Испания 800 Франция 200Это просто сделать базовый анализ и выяснить, что ваши слова разделены 50:50 между «Францией» и «Испанией». Во многих случаях это все, что у вас есть, и вы можете только измерить абсолютную частоту слов и попытаться вывести определенные отношения. В этом случае у вас есть некоторые данные о каждом из документов.
Взвешенная частота здесь явно отличается, и разбивка составляет 80:20. Другими словами, хотя «Испания» и «Франция» оба появлялись в ваших твитах по одному разу, с точки зрения ваших читателей, первое появилось 800 раз, а второе - 200 раз. Там большая разница!
Простая частота слов с использованием defaultdict
Теперь рассмотрим этот более сложный пример для аналогичного набора документов:
Document Views Франция 200 Испания 180 пляжей Испании 170 пляжей Франции 160 Лучшие пляжи Испании 160Теперь вы просматриваете документы, разбиваете их на слова и подсчитываете вхождения каждого из слов:
из коллекций import defaultdict import pandas as pd text_list = ['франция', 'испания', 'пляжи испании', 'пляжи франции', 'лучшие пляжи испании'] word_freq = defaultdict (int) для текста в text_list: для слова в тексте .split (): word_freq [word] + = 1 pd.DataFrame.from_dict (word_freq, orient = 'index') \ .sort_values (0, ascending = False) \ .rename (columns = {0: 'abs_freq'}) abs_freq испания 3 пляжи 3 франция 2 лучшие 1В приведенном выше цикле первая строка перебирает текстовый список один за другим. Вторая строка (внутри каждого документа) проходит через слова каждого элемента, разделенные пробелом (который мог быть любым другим символом ('-', ',', '_' и т. Д.)).
При попытке присвоить значение word_freq [word] возможны два сценария:
- Ключевое слово существует: в этом случае присваивание выполняется (добавление одного)
- Ключевое слово отсутствует в word_freq, в этом случае defaultdict вызывает функцию по умолчанию, которой она была назначена при первом определении, в данном случае - int.
Когда вызывается int, он возвращает ноль. Теперь ключ существует, его значение равно нулю, и он готов получить дополнительную 1 к его значению.
Хотя верхнее слово в первой таблице было «франция», после подсчета всех слов в каждом документе мы видим, что «испания» и «пляжи» связаны для первой позиции. Это важно для выявления скрытых тенденций, особенно когда список документов, с которыми вы имеете дело, исчисляется десятками или сотнями тысяч.
Взвешенная частота слов
Теперь, когда вы посчитали вхождения каждого слова в корпусе документов, вы хотите увидеть взвешенную частоту. То есть вы хотите увидеть, сколько раз слова появлялись у ваших читателей по сравнению с тем, сколько раз вы их использовали.
В первой таблице абсолютная частота слов была равномерно поделена между «испанией» и «францией», но «испания» явно имела гораздо больший вес, потому что ее значение составляло 800 против 200 или «франция».
Но какова будет взвешенная частота слов для второй, немного более сложной таблицы?
Давайте разберемся!
Вы можете повторно использовать часть кода, который вы использовали выше, но с некоторыми дополнениями:
# значение по умолчанию теперь является списком с двумя целыми числами word_freq = defaultdict (lambda: [0, 0]) # столбец `views`, который вы имели в первом DataFrame num_list = [200, 180, 170, 160, 160] # цикл теперь над текстом и числами для текста, num in zip (text_list, num_list): для слова в text.split (): # то же, что и раньше word_freq [word] [0] + = 1 # новая строка, увеличивая число значение для каждого слова word_freq [word] [1] + = число столбцов = {0: 'abs_freq', 1: 'wtd_freq'} abs_wtd_df = pd.DataFrame.from_dict (word_freq, orient = 'index') \ .rename (столбцы = столбцы) \ .sort_values ('wtd_freq', по возрастанию = False) \ .assign (rel_value = лямбда-дф: df ['wtd_freq'] / df ['abs_freq']) \ .round () abs_wtd_df.style.background_gradient (низкий уровень = 0, высокий = 0,7, подмножество = ['rel_value'])abs_freq wtd_freq rel_value испания 3 510 170 пляжей 3 490 163 Франция 2 360 180 лучшее 1 160 160
Некоторые наблюдения:
- Хотя «франция» была самой высокой фразой в целом, «Испания» и «пляжи» кажутся более заметными, когда вы выбираете взвешенную частоту.
- rel_value - это простое деление, чтобы получить значение для каждого вхождения каждого слова.
- Глядя на rel_value, вы также видите, что, хотя «france» довольно низко в метрике wtd_freq, в нем, похоже, есть потенциал, потому что значение для вхождения является высоким. Это может указывать на то, что вы, например, увеличите охват своего контента во Франции.
Вы также можете добавить некоторые другие метрики, которые показывают проценты и совокупные проценты для каждого типа частоты, чтобы вы могли лучше понять, сколько слов составляют основную часть, если таковые имеются:
abs_wtd_df.insert (1, 'abs_perc', значение = abs_wtd_df ['abs_freq'] / abs_wtd_df ['abs_freq']. sum ()) abs_wtd_df.insert (2, abs_perc_cum ', abs_wtd_df [' abs_perc '). cums ) abs_wtd_df.insert (4, wtd_freq_perc, abs_wtd_df [wtd_freq] / abs_wtd_df [wtd_freq]] sum () abs_wtd_df.style.background_gradient (низкий = 0, высокий = 0,8)abs_freq abs_perc abs_perc_cum wtd_freq wtd_freq_perc wtd_freq_perc_cum rel_value испания 3 0,333333 0,333333 510 0.335526 +0,335526 170 пляжей 3 0,333333 0,666667 0,322368 0,657895 490 163 Франция 2 0,222222 0,888889 0,236842 0,894737 360 180 лучших 1 0,111111 0,105263 1 160 1 160
Больше можно проанализировать, и с большим количеством данных вы, как правило, получите больше сюрпризов.
Так как же это может выглядеть в реальных условиях с некоторыми реальными данными?
Вы посмотрите на заголовки фильмов, посмотрите, какие слова чаще всего используются в заголовках - какая абсолютная частота - и какие слова связаны с наибольшим доходом или взвешенной частотой.
Boxoffice Mojo имеет список из более чем 15 000 фильмов вместе с их валовым доходом и рейтингами. Начните с очистки данных с помощью запросов и BeautifulSoup - вы уже можете изучить Boxoffice Mojo здесь, если хотите:
запросы на импорт из bs4 import BeautifulSoup final_list = [] для i в диапазоне (1, 156): если нет i% 10: print (i) page = 'http://www.boxofficemojo.com/alltime/domestic.htm?page = '+ str (i) +' & p = .htm 'resp = request.get (page) soup = BeautifulSoup (resp.text,' lxml ') # проб и ошибок, чтобы получить точные позиции table_data = [x.text для x в soup.select ('tr td') [11: 511]] # поместите каждые 5 значений в строку temp_list = [table_data [i: i + 5] для i в диапазоне (0, len (table_data [: - 4) ]), 5)] для temp в temp_list: final_list.append (temp) 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 boxoffice_df = pd.DataFrame.from_records (final_list) boxoffice_df.head (10) 0 1 2 3 4 0 1 Star Wars: The Force Awakens BV $ 936 662 225 2015 1 2 Аватар Фокс $ 760 507 625 2009 ^ 2 3 Черная пантера BV $ 681 084 109 201 201 3 4 Titanic Par. $ 659 363 944 1997 ^ 4 5 Юрский мир Uni. $ 652 270 625 2015 5 6 Marvel's The Avengers BV $ 623 357 910 2012 6 7 Звездные войны: последний джедай, BV $ 620 181 382 2017 7 7 The Dark Knight WB $ 534 858 444 2008 ^ 8 9 Rogue One: Звездные войны Story BV $ 532 177 324 2016 9 10 Красавица и чудовище (2017 ) BV $ 504 014 165 2017 boxoffice_df.tail (15) 0 1 2 3 4 15485 15486 The Dark Hours N / A $ 423 2005 15486 15487 2:22 Magn. $ 422 2017 15487 15488 State Park Atl $ 421 1988 15488 15489 Волшебник (2010) Рег. 406 $ 2010 15489 15490 PPF без кожи 400 $ 2014 15490 15491 Cinemanovels Mont. $ 398 2014 15491 15492 Ханна: неописуемое путешествие буддизма KL $ 396 2016 15492 15493 Квартира 143 Магн. $ 383 2012 15493 15494 The Marsh All. $ 336 2007 15494 15495 Горничная FM $ 315 2015 15495 15496 Новости с планеты Марс KL $ 310 2016 15496 15497 Троянская война WB $ 309 1997 15497 15498 Лу! Журнал Инфим Дистриб. $ 287 2015 15498 15499 Интервенция Все. $ 279 2007 15499 15500 Воспроизведение Магн. $ 264 2012Вы увидите, что некоторые числовые значения имеют некоторые специальные символы ($,, и ^), а некоторые значения фактически отсутствуют. Так что вам нужно изменить это:
na_year_idx = [i для i, x в перечислении (final_list), если x [4] == 'n / a'] # получить индексы значений 'n / a' new_years = [1998, 1999, 1960, 1973] # получил их, проверив онлайн печать (* [(i, x) для i, x в перечислении (final_list), если i в na_year_idx], sep = '\ n') print ('значения нового года:', new_years) (8003, ['8004', 'Warner Bros. 75-й юбилейный кинофестиваль', 'WB', '$ 741,855', 'n / a']) (8148, ['8149', 'Hum Aapke Dil Mein Rahte Hain', 'Eros' , '668 678 $,' н / п ']) (8197, [' 8198 ',' Пурпурная луна (переиздание) ',' Mira. ',' $ 640 945 ',' н / п ']) (10469, [ '10470', 'Amarcord', 'Jan.', '$ 125,493', 'n / a']) значения нового года: [1998, 1999, 1960, 1973] для na_year, new_year in zip (na_year_idx, new_years): final_list [na_year] [4] = new_year print (final_list [na_year], new_year) ['8004', '75-летний юбилейный кинофестиваль Warner Bros.', 'WB', '$ 741,855', 1998] 1998 ['8149', 'Hum Aapke Dil Mein Rahte Hain ',' Eros ',' 668 678 $, 1999] 1999 ['8198', 'Purple Moon (переиздание)', 'Mira.', '$ 640 945', 1960] 1960 ['10470', «Амаркорд», «Январь», «$ 125,493», 1973] 1973Теперь вы превращаете список в DataFrame pandas, называя столбцы соответствующими именами и конвертируя их в нужные вам типы данных.
import re regex = '|' .join (['\ $', ',', '\ ^']) columns = ['rank', 'title', 'studio', 'life_gross', 'year'] boxoffice_df = pd.DataFrame ({'rank': [int (x [0]) для x в final_list], # преобразовать ранги в целые числа 'title': [x [1] для x в final_list], # получить заголовки как есть ' studio ': [x [2] для x в final_list], # получить имена студий в том виде, в каком они определены как "life_gross": [int (re.sub (regex,' ', x [3])) для x в final_list], # удалить специальные символы и преобразовать в целое число 'year': [int (re.sub (regex, '', str (x [4]))) для x в final_list], # удалить специальные символы и преобразовать в целое число}) print (' lines: ', boxoffice_df.shape [0]) print (' columns: ', boxoffice_df.shape [1]) print (' \ ndata types: ') print (boxoffice_df.dtypes) boxoffice_df.head (15) строк: 15500 столбцов : 5 типов данных: продолжительность_гросса int64 ранг int64 заголовок объекта студии год объекта int64 dtype: объект life_gross ранг название студии года 0 936662225 1 BV Star Wars: Пробуждение силы 2015 1 760507625 2 Fox Avatar 2009 2 681084109 3 BV Black Panther 2018 3 65936 3944 4 Пар. Титаник 1997 4 652270625 5 Uni. Мир Юрского периода 2015 5 623357910 6 BV Marvel's Avengers 2012 6 620181382 7 BV Star Wars: Последний джедай 2017 7 534858444 8 WB The Dark Knight 2008 8 532177324 9 BV Rogue One: История Звездных войн 2016 9 504014165 10 BV Красавица и чудовище (2017) 2017 10 486295561 11 BV Finding Dory 2016 11 474544677 12 Fox Star Wars: Эпизод I - Призрачная угроза 1999 12 460998007 13 Fox Star Wars 1977 13 459005868 14 BV Мстители: Эра Альтрона 2015 14 448139099 15 WB The Dark Knight Rises 2012Слово «звезда» - одно из лучших, поскольку оно встречается в пяти из пятнадцати лучших фильмов, и вы также знаете, что в сериале «Звездные войны» еще больше фильмов, в том числе и в нескольких.
Давайте теперь воспользуемся разработанным вами кодом и посмотрим, как он работает с этим набором данных. В приведенном ниже коде нет ничего нового, вы просто помещаете все это в одну функцию:
def word_frequency (text_list, num_list, sep = None): word_freq = defaultdict (лямбда: [0, 0]) для текста, num in zip (text_list, num_list): для слова в text.split (sep = sep): word_freq [ word] [0] + = 1 word_freq [word] [1] + = num столбцов = {0: 'abs_freq', 1: 'wtd_freq'} abs_wtd_df = (pd.DataFrame.from_dict (word_freq, orient = 'index') .rename (столбцы = столбцы) .sort_values ('wtd_freq', по возрастанию = False) .assign (rel_value = lambda df: df ['wtd_freq'] / df ['abs_freq']). round ()) abs_wtd_df.insert (1 , 'abs_perc', value = abs_wtd_df ['abs_freq'] / abs_wtd_df ['abs_freq']. sum ()) abs_wtd_df.insert (2, 'abs_perc_cum', abs_wtd_df ['abs_perc']. cumsum ()) abs_wsert_df. 4, 'wtd_freq_perc', abs_wtd_df ['wtd_freq'] / abs_wtd_df ['wtd_freq']. Sum ()) abs_wtd_df.insert (5, 'wtd_freq_perc_cum', abs_wtd_df ['wtd_fre_f_f_f_c_f_f_F_F_F_F_F_DF) ['title'], boxoffice_df ['life_gross']). head () abs_freq abs_perc abs_perc_cum wtd_freq wtd_freq_perc wtd_freq_perc_cum rel_value 3055 0,068747 0,06874 7 67518342498 0,081167 0,081167 22100930,0 1310 0,029479 0,098227 32973100860 0,039639 0,120806 25170306,0 из 1399 0,031482 0,12 9709 30180592467 0,036282 0,157087 21572975,0 и 545 0,0122 028 2 028 2 028 2 0282 0282 0282 028282 0282 028282 0282 028292 0282 028292 0291 0291 0292 028292 0291 0292 028292 0291 028292 0291 028292 0291 0282 0282 0282 0282 0282,128,137,132,132,132,125,132,175,132,132,132,128,132 отлНеудивительно, что «стоп-слова» являются главными, что почти одинаково для большинства коллекций документов. Вы также дублируете их, где некоторые пишутся с большой буквы, а некоторые нет. Таким образом, у вас есть две вещи, о которых нужно позаботиться:
- Удалите все стоп-слова: вы можете сделать это, добавив новый параметр в функцию и предоставив свой собственный список стоп-слов.
- Обработайте все слова в нижнем регистре, чтобы удалить дубликаты
Вот простое обновление функции (новый параметр rm_words, а также строки 6,7 и 8):
# слова будут расширены def word_frequency (text_list, num_list, sep = None, rm_words = ('the', 'and', 'a')): word_freq = defaultdict (lambda: [0, 0]) для текста, число в zip (text_list, num_list): для слова в text.split (sep = sep): # Это должно позаботиться о игнорировании слова, если оно находится в стоп-словах, если word.lower () в rm_words: continue # .lower () делает уверен, что мы не дублируем слова word_freq [word.lower ()] [0] + = 1 word_freq [word.lower ()] [1] + = num columns = {0: 'abs_freq', 1: 'wtd_freq'} abs_wtd_df = (pd.DataFrame.from_dict (word_freq, orient = 'index') .rename (столбцы = столбцы) .sort_values ('wtd_freq', ascending = False) .assign (rel_value = lambda df: df ['wtd_freq'] / df ['abs_freq']). round ()) abs_wtd_df.insert (1, 'abs_perc', значение = abs_wtd_df ['abs_freq'] / abs_wtd_df ['abs_freq']. sum ()) abs_wtd_df.insert (2, "abs_perc_cum" , abs_wtd_df ['abs_perc']. cumsum ()) abs_wtd_df.insert (4, 'wtd_freq_perc', abs_wtd_df ['wtd_freq'] / abs_wtd_df ['wtd_freq']. sum ()) abs_wtd_df.inc_w_re_f_ (0) abs_wtd_d f ['wtd_freq_perc']. cumsum ()) abs_wtd_df = abs_wtd_df.reset_index (). rename (columns = {'index': 'word'}) вернуть abs_wtd_df из импорта коллекций defaultdicdic word_freq_df = word_frequency (boxoffice_df ['title] boxoffice_df ['life_gross'], rm_words = ['of', 'in', 'to', 'and', 'a', 'the', 'for', 'on', '&', 'is', 'at', 'it', 'from', 'with']) word_freq_df.head (15) .style.bar (['abs_freq', 'wtd_freq', 'rel_value'], color = '# 60DDFF') # E6E9EBСлово abs_freq abs_perc abs_perc_cum wtd_freq wtd_freq_perc wtd_freq_perc_cum rel_value 0 2 158 0,00443945 0,00443945 0,0137634 0,0137634 9032673058 5.71688e +07 1 звезда 45 0,0012644 0,00570385 0,00818953 0,0219529 5374658819 1.19437e + 08 2 195 человек 0,00547907 0,0111829 0,0060447 0,0279976 3967037854 2.03438e +07 3 часть 41 0,00115201 0,0123349 3262579777 0.00497129 0.0329689 7.95751e + 07 4 фильма 117 0,00328744 0,0156224 0,0378693 0,00490039 3216050557 2.74876e + 07 5 3 63 0,00177016 0,0173925 0,0427415 0,00487227 3197591193 5.07554e + 07 6 II 67 0,00188255 0,0192751 0,0046896 0,0474311 3077712883 4.5936e + 07 7 войны: 6 0,000168587 0,0194437 0,00420168 2757497155 0.0516328 4.59583e + 08 8 133 Последнее 0,003737 0,0231807 0,0557015 0,00406871 2670229651 2.00769e +07 9 Юарры 27 0,00075864 0,0239393 0,0596805 0,00397896 2611329714 9.67159e + 07 10 мне 140 0,00393369 0,00374736 0,027873 2459330128 0,0634279 1.75666e + 07 11 горшечник 10 0,000280978 0,028154 2394811427 0,00364905 0,0670769 2,39481 e + 08 12 черный 71 0,0019 9494 0,0301489 2372306467 0,00361476 0,0706917 3,34128e + 07 13 - 49 0,00137679 0,0315257 2339484878 0,00356474 0,0742564 4,77446e + 07 14 story 107 0,00300646 0,0345322 2231437526 0,00340011 0,0776565 2,08546e + 07
Давайте посмотрим на тот же DataFrame, отсортированный на основе abs_freq:
(word_freq_df.sort_values ('abs_freq', ascending = False) .head (15) .style.bar (['abs_freq', 'wtd_freq', 'rel_value'], color = '# 60DDFF'))Слово abs_freq abs_perc abs_perc_cum wtd_freq wtd_freq_perc wtd_freq_perc_cum rel_value 26 любовь 211 0,00592863 0,069542 1604206885 0,00244438 0,111399 7.60288e + 06 2 человек 195 0,00547907 0,0111829 0,0060447 0,0279976 3967037854 2.03438e + 07 24 мой 191 0,00536668 0,0618994 1629540498 0,00248298 0,106478 8.53163e + 06 15 я 168 0,00472043 0,0392526 2203439786 0.00335745 0.081014 1.31157e + 07 0 2 158 0,00443945 0,00443945 0,0137634 0,0137634 9032673058 5.71688e + 07 10 мне 140 0,00393369 0,00374736 0,027873 2459330128 0,0634279 1.75666e + 07 31 жизнь 134 0,0037651 0,0764822 0,00233839 0,123297 1534647732 1.14526e + 07 8 133 Последнее 0,003737 0,0231807 0,0557015 0,00406871 2670229651 2.00769e + 07 23 you 126 0.00354032 0.0565327 1713758853 0.00261131 0.103995 1.36013e + 07 4 фильм 117 0,00328744 0,0156224 3216050557 0,00490039 0,0378693 2,74876e + 07 14 сюжет 107 0,00300646 0,0345322 2231437526 0,002 0322 0322 0322 0322 0322 0322 0,02 0322 0322 0,02 0322,02 0322,02 0322,02 0322,02 0322,05,02,02,02,02,032,02,02,02,02,032,05,02,02,02,02,032,02,05,02,02,02,026,02,02,02,02,026,02,02,02,026,02,02,026,02,126,325,05,0 Увиделфек 2,0 ун. 2,00769,02,02,02,02,0 2,02,0 Ухитт. 2,0 ун. 2,00769e. +07 19 американец 93 0,00261309 0,0478505 1868854192 0,00284763 0,0932591 2,00952e + 07 117 девушка 90 0,0025288 0,151644 842771661 0,00128416 0,26663 9,36413e + 06 16 дней 87 0,00244451 0,0416971 2164198760 0,00329766 0,0843116 2,48758e 07
Теперь давайте визуализируем, чтобы сравнить оба и увидеть скрытые тенденции:
импортировать matplotlib.pyplot как plt plt.figure (figsize = (20,8)) plt.subplot (1, 2, 1) word_freq_df_abs = word_freq_df.sort_values ('abs_freq', ascending = False) .reset_index () plt.barh () диапазон (20), список (перевернутый (word_freq_df_abs ['abs_freq'] [: 20])), color = '# 288FB7') для i, слово в перечислении (word_freq_df_abs ['word'] [: 20]): plt. текст (word_freq_df_abs ['abs_freq'] [i], 20-i-1, s = str (i + 1) + '.' + word + ':' + str (word_freq_df_abs ['abs_freq'] [i]), ha = 'right', va = 'center', fontsize = 14, color = 'white', fontweight = 'bold') plt.text (0.4, -1.1, s = 'Сколько раз слово использовалось в фильме title; из 15500 фильмов. ', fontsize = 14) plt.text (0.4, -1.8, s =' Data: boxofficemojo.com апрель 2018. Обратная связь: @eliasdabbas ', fontsize = 14) plt.vlines (range ( 0, 210, 10), -1, 20, цвета = «серый», альфа = 0,1) plt.hlines (диапазон (0, 20, 2), 0, 210, цвета = «серый», альфа = 0,1) plt .yticks ([]) plt.xticks ([]) plt.title («Слова, наиболее часто используемые в названиях фильмов», fontsize = 22, fontweight = 'bold') # ============= plt.subplot (1, 2, 2) # plt.axis ('off') plt.barh (range (20), список (перевернутый (word_freq_df ['wtd_freq'] [: 20])), color = '# 288FB7') для i, перечисляемое слово (word_freq_df ['word'] [: 20] ): plt.text (word_freq_df ['wtd_freq'] [i], 20-i-1, s = str (i + 1) + '. '+ word +': '+' $ '+ str (round (word_freq_df [' wtd_freq '] [i] / 1000_000_000, 2)) +' b ', ha =' right ', va =' center ', fontsize = 14, color = 'white', fontweight = 'bold') plt.text (0.4, -1.1, s = 'Доход за все время за все фильмы, в названии которых содержалось слово. (Top word is "2") ", fontsize = 14) plt.text (0.4, -1.8, s = 'Сбор данных и методология: http://bit.ly/word_freq', fontsize = 14) plt.vlines (range (0, 9_500_000_000, 500_000_000), -1, 20, цвета = «серый», альфа = 0,1) plt.hlines (диапазон (0, 20, 2), 0, 10_000_000_000, цвета = «серый», альфа = 0,1) plt.xlim ((- 70_000_000, 9_500_000_000)) plt.yticks ([]) plt.xticks ([]) plt.title («Слова, наиболее связанные с доходами Boxoffice», fontsize = 22, fontweight = 'bold') plt.tight_layout (pad = 0.01) plt.show ()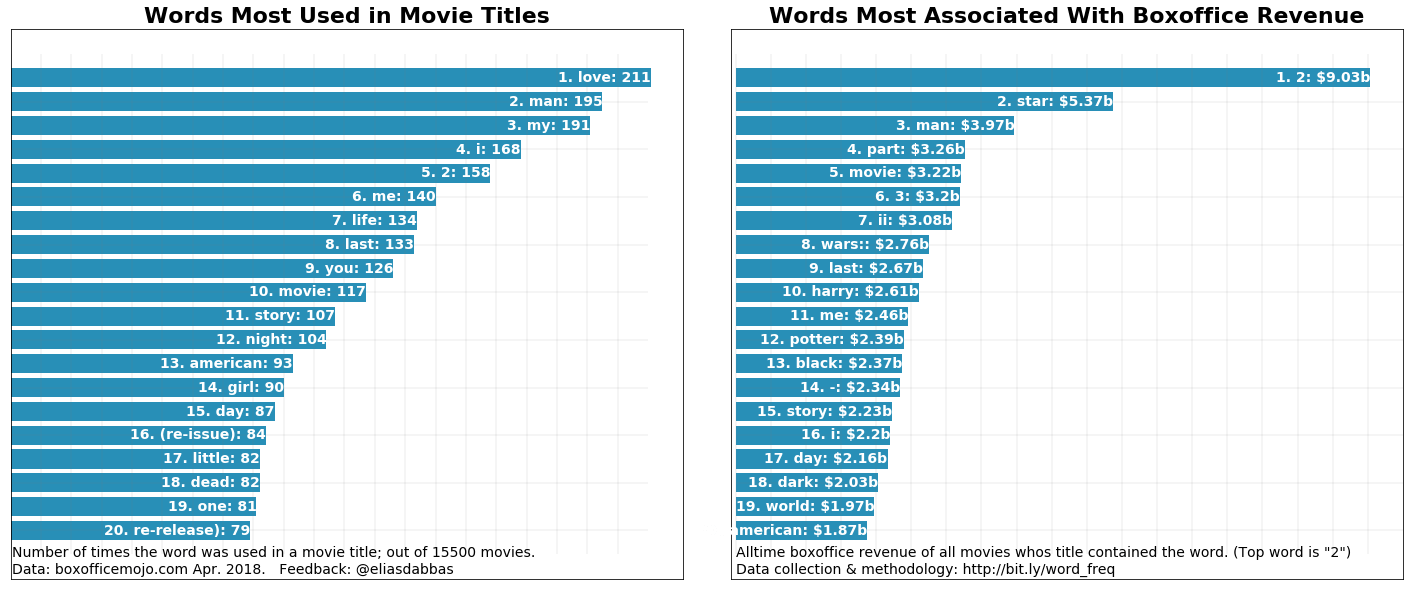
Кажется, что, по крайней мере, в умах продюсеров и писателей любовь побеждает все! Это наиболее употребительное слово во всех названиях фильмов. Однако, когда дело доходит до взвешенной частоты (кассовая выручка), она не так высока.
Другими словами, если вы посмотрите на все названия фильмов, слово «любовь» будет тем, которое вы найдете больше всего. Но при оценке того, какое слово выглядело больше всего в глазах зрителей (используя валовой доход в качестве показателя), тогда «2», «звезда» и «человек» были бы наиболее просматриваемыми или связанными с наибольшим доходом.
Просто чтобы быть ясно: это очень простые вычисления. Когда вы говорите, что взвешенная частота слова «любовь» составляет 1 604 106 767, это просто означает, что сумма брутто всех фильмов, в названии которых присутствует слово «любовь», была именно этой суммой.
Также интересно, что «2» - главное слово. Очевидно, это не слово, но это признак того, что вторые части серии фильмов составляют очень большую сумму. Так же как и «3», который находится на пятой позиции. Обратите внимание, что 'part' и 'ii' также входят в первую десятку, подтверждая тот же факт.
«Американец» и «фильм» имеют высокую относительную ценность.
Краткое примечание о стоп-словах, используемых в этой функции
Обычно вы предоставляете более полный список стоп-слов, чем здесь, особенно если вы имеете дело со статьями или сообщениями в социальных сетях. Например, пакет nltk предоставляет списки стоп-слов на нескольких языках, и их можно скачать и использовать.
Слова здесь были выбраны после нескольких проверок лучших фильмов. Многие из них обычно считаются стоп-словами, но в случае с названиями фильмов имеет смысл оставить некоторые из них, поскольку они могут дать некоторое представление. Например, слова «я», «я», «вы» могут указывать на некоторую социальную динамику. Другая причина в том, что названия фильмов - это очень короткие фразы, и мы пытаемся извлечь из них как можно больше смысла.
Вы можете определенно попробовать это с вашим собственным набором слов, и увидеть немного другие результаты.
Оглядываясь на первоначальный список названий фильмов, мы видим, что некоторые из главных слов даже не появляются в первой десятке, и это именно та идея, которую мы пытаемся раскрыть с помощью этого подхода.
boxoffice_df.head (10) life_gross rank название студии год 0 936662225 1 BV Star Wars: The Force Awakens 2015 1 760507625 2 Fox Avatar 2009 2 681084109 3 BV Black Panther 2018 3 659363944 4 Пар. Титаник 1997 4 652270625 5 Uni. Мир Юрского периода 2015 5 623357910 6 BV Marvel's Avengers 2012 6 620181382 7 BV Star Wars: Последний джедай 2017 7 534858444 8 WB The Dark Knight 2008 8 532177324 9 BV Rogue One: История Звездных войн 2016 9 504014165 10 BV Красавица и чудовище (2017) 2017Далее, я думаю, что было бы целесообразно продолжить изучение главных слов, которые интересны. Давайте отфильтруем фильмы, содержащие «2», и посмотрим:
(boxoffice_df [boxoffice_df ['title'] .str .contains ('2 | 2', case = False)] # пробелы, используемые для исключения таких слов, как '2010' .head (10)) life_gross rank название студии год 15 441226247 16 DW Shrek 2 2004 30 389813101 31 BV Хранители Галактики Том. 2 2017 31 381011219 32 WB Гарри Поттер и Дары смерти Часть 2 2011 35 373585825 36 Sony Spider-Man 2 2004 38 368061265 39 Uni. Гадкий я 2 2013 64 312433331 65 Пар. Железный Человек 2 2010 79 292324737 80 LG / S Сумерки. Сага. Рассвет: Часть 2 2012 87 281723902 88 LGF Голодные игры: Сойка-пересмешник - Часть 2 2015 117 245852179 118 BV История игрушек 2 1999 146 226164286 147 NL Rush Hour 2 2001Давайте также взглянем на главные «звездные» фильмы:
boxoffice_df [boxoffice_df ['title']. str.contains ('star | star', case = False)]. head (10) life_gross ранг студия название год 0 936662225 1 BV Звездные войны: Пробуждение Силы 2015 6 620181382 7 BV Star Войны: последний джедай 2017 8 532177324 9 BV Rogue One: История Звездных войн 2016 11 474544677 12 Fox Star Wars: Эпизод I - Призрачная угроза 1999 12 460998007 13 Fox Star Wars 1977 33 380270577 34 Fox Star Wars: Эпизод III - Месть ситхов 2005 65 310676740 66 Fox Star Wars: Episode II - Атака клонов 2002 105 257730019 106 Пар. Star Trek 2009 140 228778661 141 Пар. Звездный путь в темноту 2013 301 158848340 302 Пар. Звездный путь после 2016 годаИ, наконец, лучшие «мужские» фильмы:
boxoffice_df [boxoffice_df ['title']. str.contains ('man | man', case = False)]. head (10) life_gross rank студия название год 18 423315812 19 BV Пираты Карибского моря: Сундук мертвеца 2006 22 409013994 23 BV Iron Man 3 2013 35 373585825 36 Sony Spider-Man 2 2004 48 336530303 49 Sony Spider-Man 3 2007 53 330360194 54 WB Бэтмен против Супермена: Рассвет правосудия 2016 59 318412101 60 Пар. Железный Человек 2008 64 312433331 65 Пар. Iron Man 2 2010 82 291045518 83 WB Man of Steel 2013 176 206852432 177 WB Batman Начинается 2005 182 202853933 183 Sony The Amazing Spider-Man 2 2014Следующие шаги и улучшения
В качестве первого шага вы можете попытаться получить больше слов: названия фильмов очень короткие и много раз не передают буквальное значение слов. Например, крестным отцом считается человек, который наблюдает за крещением ребенка и обещает позаботиться об этом ребенке (или, может быть, мафиози, который убивает ради удовольствия ?!).
Еще одним упражнением может стать более подробное описание в дополнение к названию фильма. Например:
«Компьютерный хакер узнает от загадочных мятежников об истинной природе своей реальности и своей роли в войне против ее контролеров».
рассказывает нам гораздо больше о фильме, чем «Матрица».
В качестве альтернативы вы также можете воспользоваться одним из следующих способов, чтобы обогатить свой анализ:
- Лучший статистический анализ: обработка экстремальных значений / выбросов с использованием других метрик.
- Анализ текста: группировка похожих слов и тем вместе («счастливый», «счастливый», «счастливый» и т. Д.)
- Гранулярный анализ: запуск одной и той же функции для разных лет / десятилетий или для определенных производственных студий.
Вы можете быть заинтересованы в исследовании данных самостоятельно, а также других данных:
Итак, теперь вы изучили количество слов в названиях фильмов и увидели разницу между абсолютной и взвешенной частотами и то, как выход одного из них может пропустить большую часть изображения. Вы также увидели ограничения этого подхода и получили несколько советов о том, как улучшить свой анализ.
Вы прошли через процесс создания специальной функции, которую вы можете легко запустить для анализа любого подобного набора текстовых данных с помощью чисел, и знаете, как это может улучшить ваше понимание этого типа набора данных.
Попробуйте это, проанализировав эффективность ваших твитов, URL-адреса вашего сайта, ваши посты в Facebook или любой другой подобный набор данных, с которым вы можете столкнуться.
Это может быть проще просто клонировать хранилище с кодом и попробуйте сами.
Функция word_frequency является частью advertools пакет, который вы можете скачать и попробовать использовать в своей работе / исследовании.
Проверьте это и дайте мне знать! @eliasdabbas
Похожие
Ключом к успеху является простая диета • Диета Блог OXY365Диета - вы связываете со сложными блюдами и полной сменой меню? Вам нравятся простые, довольно традиционные решения и вам не хватает времени на кухонные завоевания? У меня для вас хорошие новости - существует простая диета для похудения, и потеря килограммов никогда не была такой простой, как сейчас. Несколько простых правил и готовое меню для вас - это ключ к стройной фигуре. 7 вещей, которые могут заменить 3D-технологии
Крупнейшие производители телевизоров постепенно отказываются от 3D-технологий в своих устройствах. Что может сделать просмотр фильмов лучше в этом году и в ближайшем будущем? Мы выбрали 7 вещей, которые могут заменить технологию 3D. Вы согласны с нами? 1. 4K разрешение Новогодние обещания или планы на 2017 год
... ия ... Я думаю, что все знают, как это происходит с ними. Мне кажется, что для повышения шансов на их реализацию стоит поделиться ими с кем-то. Мотивация усиливается, когда вы знаете, что кто-то болеет за вас, и вам будет стыдно, если вы не добьетесь своей цели. Это не отличается со мной и блогом. У меня есть несколько положений, связанных с этим, и чтобы мне было труднее отказаться от них, я решил представить свои планы на 2017 год в форме этой записи. Если слово сказано, то вам придется Виртуальная галерея, блог или собственный сайт? Посмотрите, какое портфолио вам нужно
Каждому фотографу нужно хорошее портфолио. Помогает построить бренд, привлечь новых клиентов и показать лучший HR. Хорошо знать, где их создавать. И что это за портфель. Зачем тебе портфолио? Портфель используется для ... хвастовства. Давайте не будем обманывать себя. Когда вы выбираете свои лучшие фотографии и знаете, что они хорошо показывают, что вы можете сделать, вам просто нужно найти хорошее место, чтобы представить их. Есть несколько таких сайтов и предназначены Учебник: CSS фиксированное позиционирование в интерактивной электронной почте
... словом, и слово появляется! Используя эту же технику, вы можете создавать электронные письма «охоты за сокровищами», в которых могут быть сделаны специальные коды, которые появятся после того, как получатель прокрутит письмо до определенной позиции. Запасы и Причуды Обработки Поскольку единственными клиентами, поддерживающими фиксированное позиционирование, являются те, которые поддерживают медиазапросы, мы изначально скрываем весь контейнер и показываем запасной Как настроить админ панель WordPress для клиентов
Как разработчику WordPress, вам постоянно приходится писать много сложного кода, чтобы создать идеальный веб-сайт для вашего клиента. Но если вы подумаете об этом, среднестатистическому пользователю WordPress нужно только позаботиться о своих сообщениях. Какой смысл отягощать их несвязанными и запутанными вариантами? Чаще всего ваши клиенты хотят простой внутренний интерфейс для управления повседневными задачами. Хотя WordPress CMS достаточно Как создать продукт в стиле Hunt с использованием плагина Hunt Theme
Веб-сайты, продвигающие курируемый контент, стали настоящей интернет-сенсацией в последнее время. С огромных сайтов, таких как BuzzFeed а также Охота за продуктом Кроме мгновенных хитов, таких как ViralNova и ViralForest, веб-дизайнеры получают прибыль влево, вправо и по центру, используя бизнес-модель, которая отличается от обычной. Я имею в виду, что большинство сайтов, занимающихся курированием контента, Введение в сетевые функции
... и Windows XP Home Edition предназначены для сетевого взаимодействия, но основной сетевой платформой является версия Professional. Если вы начнете работать с сетями, эта глава познакомит вас с этой темой. Если вам не чужды сетевая тема, эта глава обновит ваши сообщения. Концепции, связанные с сетевым взаимодействием Windows Сетевое взаимодействие не всегда должно быть сложным, хотя иногда это происходит в зависимости от приложений. Чтобы получить твердые знания, лучше всего 33 трюка в Word, которые должен знать каждый редактор
Казалось бы, редактирование текстов в Word не требует от редактора глубоких знаний Word. Но это неверное предположение. Технический недостаток в использовании основного рабочего инструмента, который является Word, может стоить нам тысячи часов в масштабах нашей карьеры, потраченных впустую на разочаровывающую борьбу с текстовым процессором. Мне нравится сравнивать работу редактора с работой ювелира. Потому что редактирование текстов в Word - это не только лингвистическая корректность, Но какова будет взвешенная частота слов для второй, немного более сложной таблицы?
Так как же это может выглядеть в реальных условиях с некоторыми реальными данными?
Htm?
Или, может быть, мафиози, который убивает ради удовольствия ?
Вам нравятся простые, довольно традиционные решения и вам не хватает времени на кухонные завоевания?
Что может сделать просмотр фильмов лучше в этом году и в ближайшем будущем?
Вы согласны с нами?
Зачем тебе портфолио?
Какой смысл отягощать их несвязанными и запутанными вариантами?